Was sind bitweise Verschiebungsoperatoren (Bit-Shift) und wie funktionieren sie?
Ich habe versucht, C in meiner Freizeit zu lernen, und andere Sprachen (C#, Java, etc.) haben das gleiche Konzept (und oft die gleichen Operatoren) ...
Ich frage mich, was Bit-Shifting (<<, >>, >>, >>>) im Kern bewirkt, welche Probleme damit gelöst werden können und welche Probleme hinter der Kurve lauern? Mit anderen Worten: ein Leitfaden für absolute Einsteiger in die Bitverschiebung in all ihren Vorzügen.









Die Bitverschiebungsoperatoren tun genau das, was ihr Name schon sagt. Sie verschieben Bits. Hier ist eine kurze (oder auch nicht so kurze) Einführung in die verschiedenen Verschiebeoperatoren.
Die Operatoren
>>ist der arithmetische (oder vorzeichenbehaftete) Rechtsschiebeoperator.>>>ist der logische (oder vorzeichenlose) Rechtsschiebeoperator.<<ist der linke Verschiebeoperator und erfüllt die Anforderungen sowohl der logischen als auch der arithmetischen Verschiebung.
Alle diese Operatoren können auf ganzzahlige Werte angewendet werden (int, long, eventuell short und byte oder char). In einigen Sprachen wird bei der Anwendung der Verschiebungsoperatoren auf einen Datentyp, der kleiner als int ist, automatisch die Größe des Operanden auf int geändert.
Beachten Sie, dass <<< kein Operator ist, da dies redundant wäre.
Beachten Sie auch, dass C und C++ nicht zwischen den Rechtsschiebeoperatoren unterscheiden. Sie bieten nur den >>-Operator an, und das Rechtsschiebeverhalten ist für vorzeichenbehaftete Typen durch die Implementierung definiert. Für den Rest der Antwort werden die C#/Java-Operatoren verwendet.
(In allen gängigen C- und C++-Implementierungen, einschließlich gcc und clang/LLVM, ist >> bei vorzeichenbehafteten Typen arithmetisch. Einige Codes gehen davon aus, aber das ist nichts, was der Standard garantiert. Es ist jedoch nicht undefiniert; der Standard verlangt von den Implementierungen, dass sie es auf die eine oder andere Weise definieren. Allerdings ist die Linksverschiebung negativer vorzeichenbehafteter Zahlen ein undefiniertes Verhalten (Überlauf vorzeichenbehafteter Ganzzahlen). Wenn Sie also keine arithmetische Rechtsverschiebung benötigen, ist es normalerweise eine gute Idee, Ihre Bitverschiebung mit vorzeichenlosen Typen durchzuführen).
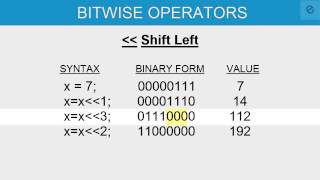
Linksverschiebung (<<)
Ganzzahlen werden im Speicher als eine Reihe von Bits gespeichert. Zum Beispiel würde die Zahl 6 als 32-Bit-Inte gespeichert werden:
00000000 00000000 00000000 00000110Wenn man dieses Bitmuster um eine Position nach links verschiebt (6 << 1), erhält man die Zahl 12:
00000000 00000000 00000000 00001100Wie Sie sehen, haben sich die Ziffern um eine Position nach links verschoben, und die letzte Ziffer auf der rechten Seite ist mit einer Null aufgefüllt. Sie können auch feststellen, dass die Verschiebung nach links der Multiplikation mit Potenzen von 2 entspricht. 6 << 1ist also gleichbedeutend mit 6 * 2, und 6 << 3ist gleichbedeutend mit 6 * 8. Ein guter optimierender Compiler wird Multiplikationen durch Verschiebungen ersetzen, wenn dies möglich ist.
Nicht-zirkuläres Verschieben
Bitte beachten Sie, dass dies keine zirkulären Verschiebungen sind. Verschiebung dieses Wertes um eine Position nach links (3.758.096.384 << 1):
11100000 00000000 00000000 00000000ergibt 3.221.225.472:
11000000 00000000 00000000 00000000Die Ziffer, die "vom Ende weg" verschoben wird, geht verloren. Sie wird nicht umgeschlagen.
Logische Rechtsverschiebung (>>>)
Eine logische Rechtsverschiebung ist das Gegenstück zur Linksverschiebung. Anstatt Bits nach links zu verschieben, werden sie einfach nach rechts verschoben. Zum Beispiel die Verschiebung der Zahl 12:
00000000 00000000 00000000 00001100um eine Position nach rechts (12 >>> 1), so erhalten wir unsere ursprüngliche 6 zurück:
00000000 00000000 00000000 00000110Wir sehen also, dass das Verschieben nach rechts einer Division durch Potenzen von 2 entspricht.
Verlorene Bits sind weg
Eine Verschiebung kann jedoch keine "verlorenen" Bits zurückgewinnen. Wenn wir zum Beispiel dieses Muster verschieben:
00111000 00000000 00000000 00000110um 4 Stellen nach links (939.524.102 << 4`), erhalten wir 2.147.483.744:
10000000 00000000 00000000 01100000und wenn wir dann zurückgehen ((939,524,102 << 4) >>> 4), erhalten wir 134,217,734:
00001000 00000000 00000000 00000110Wenn wir Bits verloren haben, können wir unseren ursprünglichen Wert nicht wiederherstellen.
Arithmetische Rechtsverschiebung (>>)
Die arithmetische Rechtsverschiebung ist genau wie die logische Rechtsverschiebung, nur dass sie nicht mit Null auffüllt, sondern mit dem höchstwertigen Bit. Der Grund dafür ist, dass das höchstwertige Bit das Vorzeichen-Bit ist, also das Bit, das positive und negative Zahlen unterscheidet. Durch das Auffüllen mit dem höchstwertigen Bit ist die arithmetische Rechtsverschiebung vorzeichenerhaltend.
Wenn wir zum Beispiel dieses Bitmuster als negative Zahl interpretieren:
10000000 00000000 00000000 01100000erhalten wir die Zahl -2.147.483.552. Wenn wir dies mit der arithmetischen Verschiebung (-2.147.483.552 >> 4) um 4 Stellen nach rechts verschieben, erhalten wir:
11111000 00000000 00000000 00000110oder die Zahl -134.217.722.
Wir sehen also, dass wir das Vorzeichen unserer negativen Zahlen erhalten haben, indem wir die arithmetische Rechtsverschiebung und nicht die logische Rechtsverschiebung verwenden. Und wieder einmal sehen wir, dass wir eine Division durch Potenzen von 2 durchführen.
Nehmen wir an, wir haben ein einzelnes Byte:
0110110Mit einer einfachen Bitverschiebung nach links erhalten wir:
1101100Die äußerste linke Null wurde aus dem Byte herausgeschoben, und eine neue Null wurde am rechten Ende des Bytes angehängt.
Die Bits rollen nicht um, sondern werden verworfen. Das heißt, wenn Sie 1101100 nach links schieben und dann nach rechts schieben, erhalten Sie nicht dasselbe Ergebnis zurück.
Eine Linksverschiebung um N ist gleichbedeutend mit einer Multiplikation mit 2N.
Eine Rechtsverschiebung um N ist (bei Verwendung von Einerkomplement) gleichbedeutend mit einer Division durch 2N und Rundung auf Null.
Bitshifting kann für wahnsinnig schnelle Multiplikationen und Divisionen verwendet werden, vorausgesetzt man arbeitet mit einer Potenz von 2. Fast alle Low-Level-Grafikroutinen verwenden Bitshifting.
In den alten Zeiten haben wir zum Beispiel den Modus 13h (320x200 256 Farben) für Spiele verwendet. Im Modus 13h wurde der Videospeicher sequentiell pro Pixel angelegt. Das bedeutete, dass man zur Berechnung des Speicherplatzes eines Pixels die folgende Rechnung anstellen musste:
memoryOffset = (row * 320) + columnDamals war die Geschwindigkeit entscheidend, daher wurden für diese Operation Bitverschiebungen verwendet.
320 ist jedoch keine Zweierpotenz. Um das zu umgehen, müssen wir herausfinden, welche Zweierpotenz zusammengenommen 320 ergibt:
(row * 320) = (row * 256) + (row * 64)Jetzt können wir das in Linksverschiebungen umwandeln:
(row * 320) = (row << 8) + (row << 6)Für ein Endergebnis von:
memoryOffset = ((row << 8) + (row << 6)) + columnJetzt erhalten wir denselben Offset wie zuvor, nur dass wir statt einer teuren Multiplikationsoperation die beiden Bitshifts verwenden... in x86 würde das ungefähr so aussehen (Anmerkung: Es ist ewig her, dass ich Assembler gemacht habe (Anmerkung des Herausgebers: ein paar Fehler korrigiert und ein 32-Bit-Beispiel hinzugefügt)):
mov ax, 320; 2 cycles
mul word [row]; 22 CPU Cycles
mov di,ax; 2 cycles
add di, [column]; 2 cycles
; di = [row]*320 + [column]
; 16-bit addressing mode limitations:
; [di] is a valid addressing mode, but [ax] isn't, otherwise we could skip the last movInsgesamt: 28 Zyklen auf irgendeiner alten CPU mit diesen Timings.
Vrs
mov ax, [row]; 2 cycles
mov di, ax; 2
shl ax, 6; 2
shl di, 8; 2
add di, ax; 2 (320 = 256+64)
add di, [column]; 2
; di = [row]*(256+64) + [column]12 Zyklen auf der gleichen alten CPU.
Ja, wir würden so hart arbeiten, um 16 CPU-Zyklen einzusparen.
Im 32- oder 64-Bit-Modus werden beide Versionen viel kürzer und schneller. Moderne Out-of-Order-Execution-CPUs wie Intel Skylake (siehe http://agner.org/optimize/) haben eine sehr schnelle Hardware-Multiplikation (niedrige Latenz und hoher Durchsatz), so dass der Gewinn viel geringer ist. Die AMD Bulldozer-Familie ist etwas langsamer, insbesondere bei der 64-Bit-Multiplikation. Bei Intel-CPUs und AMD Ryzen sind zwei Verschiebungen eine etwas geringere Latenz, aber mehr Anweisungen als eine Multiplikation (was zu einem geringeren Durchsatz führen kann):
imul edi, [row], 320 ; 3 cycle latency from [row] being ready
add edi, [column] ; 1 cycle latency (from [column] and edi being ready).
; edi = [row]*(256+64) + [column], in 4 cycles from [row] being ready.vs.
mov edi, [row]
shl edi, 6 ; row*64. 1 cycle latency
lea edi, [edi + edi*4] ; row*(64 + 64*4). 1 cycle latency
add edi, [column] ; 1 cycle latency from edi and [column] both being ready
; edi = [row]*(256+64) + [column], in 3 cycles from [row] being ready.Compiler werden dies für Sie tun: Sehen Sie, wie gcc, clang und MSVC alle shift+lea bei der Optimierung von return 320*row + col; verwenden.
Interessant ist hier vor allem, dass x86 über einen Shift-and-Add-Befehl (LEA) verfügt, der gleichzeitig kleine Linksverschiebungen und Additionen durchführen kann, mit der gleichen Leistung wie ein Add-Befehl. ARM ist sogar noch leistungsfähiger: Ein Operand eines beliebigen Befehls kann kostenlos nach links oder rechts verschoben werden. So kann die Skalierung mit einer Kompilierzeitkonstante, die bekanntermaßen eine Potenz von 2 ist, sogar effizienter sein als eine Multiplikation.
OK, zurück in die moderne Zeit... etwas Nützlicheres wäre jetzt, Bitshifting zu verwenden, um zwei 8-Bit-Werte in einer 16-Bit-Ganzzahl zu speichern. Zum Beispiel, in C#:
// Byte1: 11110000
// Byte2: 00001111
Int16 value = ((byte)(Byte1 >> 8) | Byte2));
// value = 000011111110000;In C++ sollten die Compiler dies für Sie tun, wenn Sie ein "Konstrukt" mit zwei 8-Bit-Mitgliedern verwenden, aber in der Praxis tun sie das nicht immer.
Ein Problem besteht darin, dass die folgenden Angaben (nach dem ANSI-Standard) implementierungsabhängig sind:
char x = -1;
x >> 1;x kann nun 127 (01111111) oder immer noch -1 (11111111) sein.
In der Praxis ist es meist Letzteres.