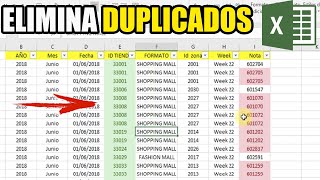
Como posso remover filas duplicadas?
Qual é a melhor maneira de remover linhas duplicadas de uma tabela bastante grande SQL Server (ou seja, mais de 300.000 linhas)?
As linhas, naturalmente, não serão duplicatas perfeitas devido à existência do campo de identidade 'RowID'.
**A minha mesa...
RowID int not null identity(1,1) primary key,
Col1 varchar(20) not null,
Col2 varchar(2048) not null,
Col3 tinyint not null









Assumindo que não há nulos, você "GRUPO POR" as colunas únicas, e "SELECCIONAR" o "MIN (ou MAX)" como a linha a ser mantida. Depois, basta apagar tudo o que não tinha uma linha de identificação:
DELETE FROM MyTable
LEFT OUTER JOIN (
SELECT MIN(RowId) as RowId, Col1, Col2, Col3
FROM MyTable
GROUP BY Col1, Col2, Col3
) as KeepRows ON
MyTable.RowId = KeepRows.RowId
WHERE
KeepRows.RowId IS NULLCaso você tenha um GUID em vez de um inteiro, você pode substituir
MIN(RowId)com
CONVERT(uniqueidentifier, MIN(CONVERT(char(36), MyGuidColumn)))Há um bom artigo sobre remoção de duplicatas no site de suporte da Microsoft. É bastante conservador - eles fazem tudo em passos separados - mas deve funcionar bem contra tabelas grandes.
Eu já usei auto-ajuda para fazer isso no passado, embora provavelmente pudesse ser fingido com uma cláusula HAVING:
DELETE dupes
FROM MyTable dupes, MyTable fullTable
WHERE dupes.dupField = fullTable.dupField
AND dupes.secondDupField = fullTable.secondDupField
AND dupes.uniqueField > fullTable.uniqueFieldAqui está outro bom artigo sobre remoção de duplicatas.
Discute porque é difícil: "SQL é baseado em álgebra relacional, e duplicados não podem ocorrer em álgebra relacional, porque duplicados não são permitidos em um conjunto."
A solução da mesa de temp, e dois exemplos mysql.
No futuro, você vai impedi-lo a nível de banco de dados, ou de uma perspectiva de aplicação. Eu sugeriria o nível da base de dados porque a sua base de dados deve ser responsável por manter a integridade referencial, os desenvolvedores apenas irão causar problemas ;)