float和double之间的区别是什么?
我读过关于双精度和单精度之间的区别。然而,在大多数情况下,"float "和 "double "似乎是可以互换的,也就是说,使用一个或另一个似乎不会影响结果。情况真的是这样吗?什么时候浮点数和双数可以互换?它们之间有什么区别?

![float and double in c [2021]](https://img.youtube.com/vi/4hCjq4MVa1k/mqdefault.jpg)







巨大的差异。
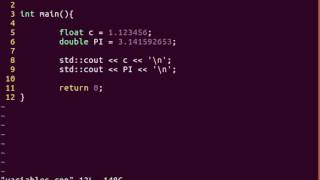
顾名思义,double`的精度是float`[1]的2倍。
一般来说,一个double有15位小数点的精度,而float有7位。
这里'是如何计算位数的。
{fnTahomafs10bord0shad01cH00FFFF}>
double有52个mantissa位+1个隐藏位。
log(253)÷log(10)=15.95位数。
float有23个mantissa位+1个隐藏位。 log(224)÷log(10)=7.22位。
这种精度损失可能会导致在重复计算时积累更大的截断误差,例如:{{6656520}}}。
float a = 1.f / 81;
float b = 0;
for (int i = 0; i < 729; ++ i)
b += a;
printf("%.7g\n", b); // prints 9.000023而
double a = 1.0 / 81;
double b = 0;
for (int i = 0; i < 729; ++ i)
b += a;
printf("%.15g\n", b); // prints 8.99999999999996另外,float的最大值约为3e38,但double约为1.7e308,所以用float可以打出"无穷大"。
(即
对于一些简单的事情,例如,计算60的阶乘,使用 "float "比使用 "double "更容易。
计算60的阶乘。
在测试过程中,可能有一些测试用例包含了这些巨大的数字,如果你使用浮点数,可能会导致你的程序失败。
当然,有时候,即使是double也不够精确,因此我们有时候会有long double[1]</sup>。
(上面的例子在Mac上给出了9.000000000000000066),但是所有的浮点类型都会出现舍入误差,所以如果精度非常重要(如
货币处理),你应该使用int或分数类。
此外,不要用+=来求很多浮点数的和,因为错误会迅速积累。
如果你使用的是Python,请使用fsum。
否则,请尝试实现 Kahan 求和算法。
&lt;sup>[1].C和C++标准没有规定 "float"、"double "和 "long double "的表示方法。
C和C++标准没有规定float、double和long double的表示方法。
有可能这三种都是以IEEE双精度的方式实现的。
然而,对于大多数架构(gcc、MSVC;
x86、x64、ARM)"float "确实是IEEE单精度浮点数(二进制32),"double "是IEEE双精度浮点数(二进制64).
以下是标准C99(ISO-IEC 9899 6.2.5 §10)或C++2003(ISO-IEC 14882-2003 3.1.9 §8)标准的内容。
有三种浮点类型。
float',double', 和long double'.double类型提供的精度至少与float相同,long double类型提供的精度至少与double相同。float类型的值集是double类型的值集的一个子集;double类型的值集是long double`类型的值集的一个子集。
C++标准补充道。
浮点类型的值表示是由实施者定义的。
我建议看一下优秀的What Every Computer Scientist Should Know About Floating-Point Arithmetic,该书深入地介绍了IEEE浮点标准。你会了解到表示的细节,你会意识到幅度和精度之间有一个权衡。浮点表示法的精度随着幅度的减少而增加,因此-1和1之间的浮点数字是精度最高的。
给出一元二次方程。 x2 &减; 4.0000000 x + 3.9999999 = 0,精确到10位有效数字的根数为,r1 = 2.000316228和r2 = 1.999683772。
使用float和double,我们可以写一个测试程序。
#include <stdio.h>
#include <math.h>
void dbl_solve(double a, double b, double c)
{
double d = b*b - 4.0*a*c;
double sd = sqrt(d);
double r1 = (-b + sd) / (2.0*a);
double r2 = (-b - sd) / (2.0*a);
printf("%.5f\t%.5f\n", r1, r2);
}
void flt_solve(float a, float b, float c)
{
float d = b*b - 4.0f*a*c;
float sd = sqrtf(d);
float r1 = (-b + sd) / (2.0f*a);
float r2 = (-b - sd) / (2.0f*a);
printf("%.5f\t%.5f\n", r1, r2);
}
int main(void)
{
float fa = 1.0f;
float fb = -4.0000000f;
float fc = 3.9999999f;
double da = 1.0;
double db = -4.0000000;
double dc = 3.9999999;
flt_solve(fa, fb, fc);
dbl_solve(da, db, dc);
return 0;
} 运行程序给我。
2.00000 2.00000
2.00032 1.99968注意,数字不大',但使用浮点还是会有取消效果。
(事实上,上述方法并不是使用单精度或双精度浮点数解二次方程的最佳方法,但即使使用[更稳定的方法][1],答案也不会改变)。
[1]: http://en.wikipedia.org/wiki/Quadratic_equation#Floating_point_implementation
- 一个双数是64,单精度 (float)是32位。
- 双倍数有一个更大的尾数(实数的整数位)。
- 任何不准确的地方在双数中都会更小。
浮点计算中涉及的数字大小不是最重要的。 相关的是正在进行的计算。
从本质上讲,如果你正在执行一个计算,结果是一个无理数或循环小数,那么当这个数字被压缩到你正在使用的有限大小的数据结构中时,就会出现四舍五入的错误。 由于double的大小是float的两倍,那么四舍五入的误差就会小很多。
测试可能会特别使用会导致这种错误的数字,因此测试了你在代码中使用了适当的类型。
类型float,长32位,精度为7位。 虽然它可以存储范围非常大或非常小的值(+/- 3.4 10^38或 10^-38),但它只有7位有意义的数字。
类型双,64位长,有更大的范围(*10^+/-308)和15位精度。
类型long double名义上是80位,尽管为了对齐的目的,一个给定的编译器/操作系统配对可能会将其存储为12-16个字节。 长双的指数实在是大得可笑,应该有19位精度。 微软以其无限的智慧,将long double限制为8个字节,和普通的double一样。
一般来说,当你需要一个浮点值/变量时,只要使用类型double即可。 表达式中使用的字面浮点值默认会被视为双倍,大多数返回浮点值的数学函数都会返回双倍。 如果你只使用双倍,你会省去很多头痛的问题和类型转换。
我刚刚遇到了一个错误,我花了很长时间才弄清楚,而且有可能给你一个很好的浮点精度的例子。
#include <iostream>
#include <iomanip>
int main(){
for(float t=0;t<1;t+=0.01){
std::cout << std::fixed << std::setprecision(6) << t << std::endl;
}
}输出是
0.000000
0.010000
0.020000
0.030000
0.040000
0.050000
0.060000
0.070000
0.080000
0.090000
0.100000
0.110000
0.120000
0.130000
0.140000
0.150000
0.160000
0.170000
0.180000
0.190000
0.200000
0.210000
0.220000
0.230000
0.240000
0.250000
0.260000
0.270000
0.280000
0.290000
0.300000
0.310000
0.320000
0.330000
0.340000
0.350000
0.360000
0.370000
0.380000
0.390000
0.400000
0.410000
0.420000
0.430000
0.440000
0.450000
0.460000
0.470000
0.480000
0.490000
0.500000
0.510000
0.520000
0.530000
0.540000
0.550000
0.560000
0.570000
0.580000
0.590000
0.600000
0.610000
0.620000
0.630000
0.640000
0.650000
0.660000
0.670000
0.680000
0.690000
0.700000
0.710000
0.720000
0.730000
0.740000
0.750000
0.760000
0.770000
0.780000
0.790000
0.800000
0.810000
0.820000
0.830000
0.839999
0.849999
0.859999
0.869999
0.879999
0.889999
0.899999
0.909999
0.919999
0.929999
0.939999
0.949999
0.959999
0.969999
0.979999
0.989999
0.999999如你所见,0.83之后,精度明显下降。
但是,如果我把t设置成双倍,这样的问题就不会发生了'。
我花了五个小时才意识到这个小错误,这毁了我的程序。
当使用浮点数时,你不能相信你的本地测试会和服务器端的测试完全一样。 环境和编译器很可能在你的本地系统和最终测试运行的地方是不同的。 我曾经在一些TopCoder比赛中多次看到这个问题,特别是当你试图比较两个浮点数时。
内置的比较操作不同,比如当你用浮点数比较2个数字时,数据类型的不同(即浮点数或双数)可能导致不同的结果。 浮点或双数)可能会导致不同的结果。